The intent of this page is to explain, in simple terms, the research conducted by eTRAP for the benefit of the wider, non-academic or non-expert community. It is our blackboard, a space where we collect and formulate our thoughts and, therefore, under constant review. Should you have any questions or corrections, please feel free to leave us a comment below!
If you wish to cite this page, you may do so as:
Franzini, G., Franzini, E., Büchler, M. (2016) Historical Text Reuse: What Is It?. <http://www.etrap.eu/historical-text-re-use/>
[This page was last updated on: 2 October 2016]
What is text reuse?
At its most basic level, text reuse is a form of text repetition or borrowing. Text reuse can take the form of an allusion, a paraphrase or even a verbatim quotation, and occurs when one author borrows or reuses text from an earlier or contemporary author. The borrower, or quoting author, may wish to reproduce the text of the quoted author word-for-word or reformulate it completely. We call this form of borrowing “intentional” text reuse. “Unintentional” text reuse can be understood as an idiom or a winged word, whose origin is unknown and that has become part of common usage.
Why study text reuse?
We all express ourselves differently and some words convey emotions or intention better than others. Consider, for example, the difference between:
“Pass the salt” and “Could you pass the salt, please?“
Same concept, same need, different tone. We all agree that the first request comes across as rude, right? But why? We know why: unlike the second request, it doesn’t contain the courtesy word ‘please’. But even if it did, it would still sound somewhat rude: “Pass the salt, please”. It is only when ‘please’ is combined with the conditional ‘could’ that a rude command becomes a polite request.
Depending on the circumstances or on the intention, our choice of words is very important. With regard to the research described here, text reuse tells us a lot about the intention of the quoting authors and their interpretation of the text they reuse or allude to. Why, for instance, do quoting authors borrow text but reformulate it in their own words? How does their word choice and the language they write in change the ‘original text’? Scholars working in the field of text reuse study the relationship between quoted and quoting authors but also that between quoting authors themselves. By doing so, they hope to uncover the intentions or rationale behind the authors’ choice of words with a view to learning more about the historical, social and temporal contexts of a text, and to, in some cases, tracing the origin of the quote.
Reuses take various forms. The figure below illustrates reuse styles or types:
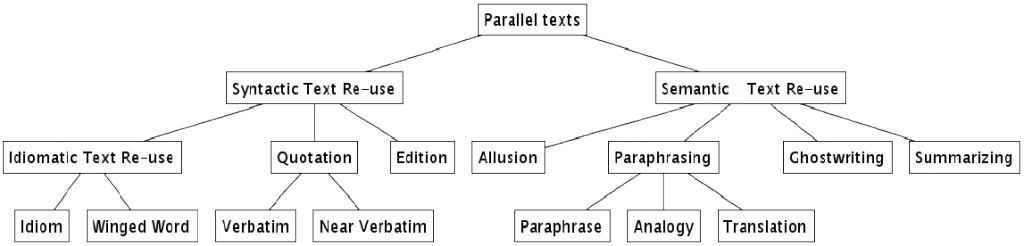
All of the above styles are forms of text re-purposing used to convey a message or a concept in different ways. Reuse can happen within a single language or across multiple languages, be those modern or ancient. However, historical text reuse, that is, reuse occurring in ancient languages, is more complex. Why? Ancient languages come with a higher level of uncertainty and diversity. What do we mean by this? Well, some ancient texts, for example, survive only in fragmentary condition; accidental or deliberate errors scribes made when copying manuscript text leave us wondering what the reason behind this ‘noise’ might be; ancient languages and dialects are less standardised, with their evolution spanning centuries, if not thousands of years; unlike today, verbatim quotes in ancient sources were not always visually enclosed in quotation marks, making it hard for us to discern reuse from ‘original’ text; finally, some authors quote other authors we know nothing about or whose works do not survive – imagine reconstructing the text of a lost author via a later quoting author, wouldn’t that be cool? Text reuse represents one approach towards such discoveries.
But enough with definitions and explanations! Let’s look at a concrete examples, “because there are several!” (says Mr. Collins in the BBC adaptation of Jane Austen’s Pride and Prejudice). See? Reuse!
Text reuse within a single language
The table below illustrates how the same concept is formulated and reused in the Ancient Greek authors Alcaeus, Plato and Theocritus:
| Author (Date) | Greek Text. Work (Edition) | English Translation (Translator) |
| Alcaeus (6th cent. BC) |
οἶνος […] καὶ αλάθεα Fragment 366 (Greek text taken from Easby-Smith’s 1901 edition). |
“wine […] and truth” (Translated by James Easby-Smith). |
| Plato (ca. 427-347 BC) |
οἶνος […] ἦν ἀληθής Symposium 217e (Greek text taken from Jahn’s 1864 edition). |
“wine […] is truthful” (Translated by Seth Benardete). |
| Theocritus (3rd cent. BC) |
οἶνος […] καὶ αλάθεα Idyll 29 (Greek text taken from Cholmeley’s 1909 edition). |
“[..]now that you and I are drinking, we must fain be men of truth” (Translated by J. M. Edmonds). |
As you’ll notice, the Greek text varies slightly across authors but the message is the same: in wine lies truth. Sentences or phrases like the example above have been quoted so many times over the centuries that it’s often difficult to identify their first occurrence. This uncertainty, combined with their popularity, turns these sentences into sayings, to the point that it’s hard for us to tell whether the later author is referring to the earlier author or simply quoting the sentence independent of its maker because, like us, (s)he doesn’t know whom it belongs to. In our example, both Plato and Theocritus do not explicitly attribute these words to Alcaeus but quote them as sayings or proverbs by introducing their sentence with the Ancient Greek equivalent of “it is said that….”. [Just to be clear, the fact that Alcaeus here is the earlier author does not mean that he’s responsible for coining this expression. To eTRAP’s knowledge, it’s the earliest surviving occurrence but we don’t know if it’s the first.]

As the Italian Renaissance statesman Francesco Guicciardini once wrote:
“[…] proverbs, though differently expressed, are found among all nations. And this because these spring from experience or from the observation of things, which are everywhere the same or similar.“
This similarity of observations and experience is preserved in and passed on by other languages. In our case, these words are more famously known in their later Latin translation In vino veritas.
Text reuse across multiple languages
Studying reuse within one language is one thing. Studying it across multiple is another. Let’s take our example again:
| Language | Text | Parts of speech | Literal English translation |
| Ancient Greek | οἶνος – καὶ – αλάθεα | noun – conjunction – noun | wine – and – truth |
| Latin | In – vino – veritas | preposition – noun – noun | In – wine – truth |
As you can see, the only things these two sentences share are the nouns and the concept of wine and truth. Everything else is different: alphabet, word order and case. A modern-day example of text reuse across languages is the following idiom:
| Language | Text | English translation |
| English | Comparing apples and oranges | – |
| French | Comparer des pommes et des poires | Comparing apples and pears |
| German | Äpfel mit Birnen vergleichen | Comparing apples and pears |
| Spanish | Comparar papas y boniatos | Comparing potatoes and sweet potatoes |
Again, same message, similar mode of expression but different words. However, both the historical and the modern language examples assume some level of knowledge of the languages in question and, in the second case, an understanding of the idiom. How do we train those who don’t have this knowledge, whether humans or computers, to detect reuse? Better still, how can we train computers to help people interested in identifying reuse? These are only some of the questions this research builds upon.
This research is not restricted to the Humanities but has parallels in many other disciplines, including Bioinformatics, Computer Science and Memetics.
Identifying allusions
A recent conversation with Dr. Christian Schwaderer, a humanist whose project in Tübingen will produce a new edition of Adelbert of Heidenheim’s Relatio, brought up a great example of an allusion which only a specialist, like Christian, is able to identify. Christian has kindly allowed us to reproduce it here.
The first text is the ‘original’ work, so to speak, written by Wolfhard of Herrieden in the 9th century:
Quo audito, vir illustris a loco quo sederat illico prosilivit, et animo consternatus, quare ad ostium nobilis persona et Omnipotentis ancilla constiterit, requisivit. Illa vero non sine causa se venisse asseruit. Tum vir memoratus cum omni veneratione eam in domo excepit, et omnem famulatum debitae servitutis exhibuit. (Ex Wolfhardi Haserensis miraculis s. Waldburgis Monheimensibus, ed. Oswald Holder-Egger (MGH SS 15,1, Hannover 1887) c. 3 p. 540)
The following text was written by Adelbert of Heidenheimin in the 12th century:
Tunc paterfamilias audito nomine Walpurgae de sede sua prosiliuit et miratus tam nobilis et tam sanctae virginis adventum, studiossime totam domum emundavit et omnibus quae ocolus sanctitatis eius offendere possunt, detersis benignissime eam in domum sua, recepit et omne humanitatis et devotionis obsequium ei exhibuit. (Adelbert of Heidenheim, Relatio, ed. Jakob Gretser (Ingolstadt 1617) p. 330-331. New edition by Christian Schwaderer here)
You don’t have to be a Latinist, nor indeed know any Latin at all, to pick up the word similarity between the two texts (highlighted in bold). However, it does take a specialist to, first, assess whether the two authors are talking about the same thing and, second, to decide whether Adelbert intentionally reuses Wolfhard.
While visually similar, the number of shared words is not significant and some of these have been adapted to fit the differing syntax. An expert who knows the subject matter can make informed inferences, but non-specialists might overlook this similarity, especially if these text snippets are taken out of context and not enclosed in expected quotation marks.
Regardless of our knowledge of these works and their authors, as humans we are at least able to draw some conclusions, be those informed or intuitive. But what about a computer? How would a machine be able to independently make these connections? The short answer is: it can’t. Yet. But why? The first text in our example contains some 50 words. Out of these, only 10 words (or 7 snippets, in bold) form the text reuse of this allusion. When configuring a computer model for such a low overlap, results yielded include many “false friends” of linked text passages which feature the same common keywords but do not refer to each other. Technically speaking, the recall is increased but the precision is very low. This effect becomes significantly stronger when the “reuse window” gets bigger. More than 90% of the text reuse can be observed in a window of 10 or fewer words.
Let us assume we give the computer the two *complete* texts of Wolfhard and Adelbert, not just the above snippets. Our first command to the computer might be:
“Compare these two texts and tell me if they’re similar”
This question assumes that a computer scientists has created an algorithm (1) which the computer uses to check similarity. The algorithm or script might translate as: “if a word in text A and in text B share 3 or more identical letters in sequence, mark this as a similarity”. This algorithm is very basic and will bring up A LOT of similarity, most of which will not be of interest to us. As you can see from our Latin example, many two-three letter words, such as stop-words, would be marked as similar by our algorithm. This is the type of similarity we don’t care about as it is common to all Latin texts, not just to Wolfhard and Adelbert. So what do we do? We create a new algorithm (2), which will strip our texts of all stop-words, and ask the computer to run (2) before (1). The results we’ll get from these two operations will be more refined and relevant to our command. But what now? How do we ascertain whether the similarity is indicative of reuse or purely coincidental? One factor that might help us answer this question is the distance between words. If these similar words also share a similar word order, then the likelihood of them being a reuse is high. But how close do they have to be to qualify as reuses? What are the minimum ‘similar word’ and ‘similar word order’ requirements to label text as a reuse? The answer to this question depends on the language under investigation. And even if we did establish a minimum requirement or ‘ground truth’, the computer might still make a mistake. An allusion, after all, doesn’t necessarily have to reuse the same words, it could just as well be using synonyms. So unless the texts are obviously similar, how can we be sure that the similarity our computer reveals to us is in fact an intentional reuse and allusion? We can’t be sure and so our next command might be:
“Confirm this similarity is not coincidental”
In order to process this request, the computer needs to be able to understand the message the text is conveying. The computer sees the words but doesn’t understand what they mean. The same concept could be equally expressed using different words in semantic relation such as synonyms, co-hyponyms, hypernyms or hyponyms. What then? Well, at this point, we need to help the computer by supplying it with a dictionary or a thesaurus and teach which synonyms are more likely to be used and how they correspond to the ‘original’ word. At the same time, we need to tell it how these synonyms must be used (individually or in combination with other words?) in order to retain the meaning of the sentence. But of course, these synonyms could be combined in multifarious ways, many of which we humans might not even consider. Complicated, right? Yes, and the truth is: we can’t feed the computer every single possibility because there are simply too many. We need to come up with other algorithms that will allow us to study the paradigmatic relations between words and thus more effectively address our questions. This is the current task of scholars working in the field and, as you’ll have understood by now, it’s not an easy one. Today, a computer needs significant time to identify a loose reuse. And computers can only be so fast – the laws of physics cannot be changed! We need to optimise, to figure out more ingenious ways of retrieving information and to give computers as much training data as we possibly can. Think of Google Translate, for example. One can translate a sentence in so many different ways, depending on its purpose and its context. It is only by learning by example that Google Translate can hope to improve its algorithms and, thus, its translations. Like Statistics, the cleaner and bigger the data, the higher the accuracy of the results.
Does using computers make sense?
At first glance, this all seems rather discouraging. However, comparisons of manual (by scholars) and automatic identification of text reuse have shown that most reuses in scholarly-collected data are easily identifiable by computers too (Büchler et al., 2012). Büchler et al. (2012) report that out of about 350 text passages, scholars identified “only” two paraphrases or allusions that the computer had not found, while the computer found much more relevant data-sets than the 350 scholarly annotated passages. This strongly relies on how scholars identify text reuse. On unknown texts scholars and the computer have similar problems in identifying additional paraphrased or alluded-to text passages.
Where does the research stand?
The research thus far has only been conducted on text reuse we know is there, on text we know has been reused by another author. This assumption has helped us create a first computational tracer but one that can only pick-up close reuses, that is, texts that share a substantial number of words which suggest the two texts are related. Think, for example, of Turnitin, the academic plagiarism checker universities all over the world use to assess the originality of student essays and theses. Turnitin’s algorithms flag up plagiarism by comparing student coursework against the internet and various databases through verbatim detection. Our techniques are very similar to those of Turnitin and while they work very well with word-for-word detection, they are not suitable for looser reuses. Much work and refinement remains to be done here in order to help computers identify less obvious forms of quoting or allusions. This is no mean feat and we need all the humanist and computer science help we can get.
The big questions we’re currently addressing are: What are the elements in text reuse that flag up text as a reuse? In other words, are there common clues or minutiae that might help a computer discern original text from ‘borrowed’ text? How can the computer alone know when one author is quoting another? Can it? If so, (how) can it quantify reuse unknown to us in our textual heritage?
Relevance of text reuse in Big Data

Thanks to the digital transformation of historical documents, the amount of digitally available data is growing exponentially. This does not only allow us to find more parallels between data-sets but also to obtain complete views and study the influence of historical works. A temperature map, for instance, can help us explore which work or which parts of a work have been quoted more frequently than others, or how much of a work is source aggregation and how much is original. The temperature map to the right here was generated from Thesaurus Linguae Graecae (TLG) data and shows how frequently these Greek authors are quoted by contemporary or later authors [each bar represents the number of words/works the TLG possesses for that author, whereby black indicates no reuse and yellow a high occurrence of reuse].
Reuse in other contexts
You might not realise it, but reuse, be it textual, pictorial or oral, is ubiquitous: from poetry to art, to film, business and music, the examples of reuse one could quote are numerous and they all play a particular role. Below are some of our favourites.
Reuse of biblical verse in medieval manuscripts

Biblical scenes can often be found in medieval illuminated manuscripts. The example on the left here is a funny visual reuse of Matthew 4:8 in Beinecke MS 425 (France, ca. 1470-75, fol. 48r).
“Again, the devil took Him up onto an exceeding high mountain, and showed Him all the kingdoms of the world and the glory of them“ (text from King James 21, the updated version of the 1611 King James English translation of the Bible).
Note how differently text and image convey the same idea. The solemnity of the former is, in our example, somewhat mocked by the playfulness of the latter. What do these contrasting mediums tell us about the intention of the scribe and of the illuminator, respectively? Why the contrast? Who were these depictions intended for?
Reuse of art in film
 |
  |
Reuse of poetry in music
The example below is a reuse of poetry in music. Eurythmics singer Annie Lennox makes the first three stanzas of Christopher Marlowe’s The Passionate Shepherd to His Love (1590s) her own in the 2002 song Live with me and be my love.
| Christopher Marlowe, The Passionate Shepherd to His Love | Annie Lennox, Live with me and be my love |
| Come live with me and be my love, And we will all the pleasures prove, That Valleys, groves, hills, and fields, Woods, or steepy mountain yields. And we will sit upon the Rocks, Seeing the Shepherds feed their flocks, By shallow Rivers to whose falls Melodious birds sing Madrigals. And I will make thee beds of Roses And a thousand fragrant posies, […Continues…] |
Live with me, and be my love, And we will all the pleasures prove By hills and valleys, dales and fields, And all the pleasant pastures yields. There will we sit upon the rocks, And see the shepherds feed their flocks, By shallow rivers, by whose falls Melodious birds sing madrigals. There will I make thee a bed of roses, With a thousand fragrant posies. [End] |
Reuse of myths in art, and then in poetry
W. H. Auden wrote the poem Musée des Beaux Arts just before the beginning of World War II, inspired by a painting he saw in the homonymous museum in Brussels. The painting, a work by Pieter Brueghel and named Landscape with the fall of Icarus, represents the indifference of people who carry on with their daily lives ignoring the sorrows of others. The painting in turn captures the famous myth of Icarus, the son of the inventor Daedalus, who flew too close to the sun and plunged to his death in the waters below.

W. H. Auden, Musée des Beaux Arts
About suffering they were never wrong,
The old Masters: how well they understood
Its human position: how it takes place
While someone else is eating or opening a window or just walking dully along;
How, when the aged are reverently, passionately waiting
For the miraculous birth, there always must be
Children who did not specially want it to happen, skating
On a pond at the edge of the wood:
They never forgot
That even the dreadful martyrdom must run its course
Anyhow in a corner, some untidy spot
Where the dogs go on with their doggy life and the torturer’s horse
Scratches its innocent behind on a tree.
In Breughel’s Icarus, for instance: how everything turns away
Quite leisurely from the disaster; the ploughman may
Have heard the splash, the forsaken cry,
But for him it was not an important failure; the sun shone
As it had to on the white legs disappearing into the green
Water, and the expensive delicate ship that must have seen
Something amazing, a boy falling out of the sky,
Had somewhere to get to and sailed calmly on.
Bibliography & works cited
Here’s a list of publications you can consult for more (detailed) information. You can also keep up-to-date with the latest developments in Historical Text Reuse by joining the Historical Text Reuse Google Group or following the Historical Text Reuse Zotero Group.
- Almas, B., Berti, M. (2013) ‘Perseids Collaborative Platform for Annotating Text Re-uses of Fragmentary Authors’, In: (Proceedings) 1st International Workshop on Collaborative Annotations in Shared Environment: Metadata, Vocabularies and Techniques in the Digital Humanities, DH-CASE ’13, New York, NY, USA. ACM.
- Alzahrani, S. M. et al. (2012) ‘Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’. In: (Proceedings) IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(2), pp. 133–149.
- Büchler, M. et al. (2012) ‘Increasing Recall for Text Re-use in Historical Documents to Support Research in the Humanities’. In: (Proceedings) Second International Conference on Theory and Practice of Digital Libraries, Vol. 7489, pp. 95–100 [Online]. DOI: 10.1007/978-3-642-33290-6_11
- Büchler, M. et al. (2013) ‘Historical Relevance Feedback Detection by Text Re-use Networks’. Leonardo, 46(3), p. 276.
- Büchler, M. et al. (2014) ‘Towards a Historical Text Re-use Detection’. In C. Biemann & A. Mehler (eds.) Text Mining, Theory and Applications of Natural Language Processing, pp. 221–238. Springer International Publishing. [Online] DOI: 10.1007/978-3-319-12655-5_11
- Büchler, M., Geßner, A. (2009) ‘Citation Detection and Textual Reuse on Ancient Greek texts’. In DHCS 2009–Chicago Colloquium on Digital Humanities and Computer Science.
- Büchler, M. et al. (2010) ‘Unsupervised Detection and Visualisation of Textual Reuse on Ancient Greek Texts’, Journal of the Chicago Colloquium on Digital Humanities and Computer Science, 1(2).
- Cedeño, A. B. et al. (2010) ‘Word Length n-Grams for Text Re-use Detection’. In A. Gelbukh (ed.) Computational Linguistics and Intelligent Text Processing, Vol. 6008 of Lecture Notes in Computer Science, pp. 687–699 [Online]. DOI: 10.1007/978-3-642-12116-6_58
- Cedeño, A. B. (2012) ‘On the Mono- and Cross-language Detection of Text Reuse and Plagiarism’. Thesis.
- Clough, P. et al. (2002) ‘METER: MEasuring TExt Reuse’.In: (Proceedings) 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, pp. 152–159, Stroudsburg, PA, USA. Association for Computational Linguistics.
- Coffee, N. et al. (2012) ‘Intertextuality in the Digital Age’. In: (Proceedings) Transactions of the American Philological Association, 142(2), pp. 383–422.
- Coffee, N. et al. (2013) ‘The Tesserae Project: intertextual analysis of Latin poetry’. Literary and Linguistic Computing, 28(2), pp. 221–228.
- Colavizza, G., Infelise, M., Kaplan, F. (2015) ‘Mapping the Early Modern News Flow: An Enquiry by Robust Text Reuse Detection’, Social Informatics, Lecture Notes in Computer Science, Vol. 8852, pp. 244-253 [Online]. DOI: 10.1007/978-3-319-15168-7_31
- C. V. R. de Camargo (2014) ‘Creating an automatic method for generating references for a commented edition of a literary text’. In: (Proceedings) Greek and Latin in an Age of Open Data. Digital Humanities-University of Leipzig.
- Forstall, C. et al. (2014) ‘Modeling the scholars: Detecting intertextuality through enhanced word-level n-gram matching’, Literary and Linguistic Computing [Online]. DOI: http://dx.doi.org/10.1093/llc/fqu014
- Ganascia, J. G., Glaudes, P., Del Lungo, A. (2014) ‘Automatic Detection of Reuses and Citations in Literary Texts’, Literary and Linguistic Computing, 29(3), pp. 412-421 [Online]. DOI: 10.1093/llc/fqu020
- Hohl Trillini, R., Quassdorf, S. (2010) ‘A ’key to all quotations’? A corpus-based parameter model of intertextuality’. Literary and Linguistic Computing, 25(3), pp. 269–286.
- Jordanous, A. et al. (2012) ‘Exploring manuscripts: sharing ancient wisdoms across the semantic web’. In: (Proceedings) 2nd International Conference on Web Intelligence, Mining and Semantics, WIMS ’12, New York, NY, USA. ACM.
- Kane, A., Tompa, F. W. (2011) ‘Janus: the intertextuality search engine for the electronic Manipulus florum project’. Literary and Linguistic Computing, 26(4), pp. 407–415.
- Lee, J. (2007) ‘A Computational Model of Text Reuse in Ancient Literary Texts’. In: (Proceedings) 45th Annual Meeting of the Association of Computational Linguistics, pp. 472–479, Prague, Czech Republic. Association for Computational Linguistics.
- Li, W. (2015) Overview of Natural Language Processing, May 27.
- Mittelbach, A. et al. (2010) ‘Automatic Detection of Local Reuse Sustaining TEL: From Innovation to Learning and Practice’. Vol. 6363 of Lecture Notes in Computer Science, pp. 229-244. Springer Berlin / Heidelberg, Berlin & Heidelberg [Online]. DOI: 10.1007/978-3-642-16020-2_16
- Neuman Y, Assaf D, Cohen Y, Last M, Argamon S, Howard N, et al. (2013) ‘Metaphor Identification in Large Texts Corpora’. PLoS ONE 8(4): e62343. doi:10.1371/journal.pone.0062343.
- Olsen, M. et al. (2010) ‘Something borrowed: sequence alignment and the identification of similar passages in large text collections’, Digital Studies/Le champ numérique, 2(1).
- Sánchez-Vega, F. et al. (2010) ‘Towards Document Plagiarism Detection Based on the Relevance and Fragmentation of the Reused Text’. In G. Sidorov, A. Hernández Aguirre, & C. A. Reyes García (eds.), Advances in Artificial Intelligence, Vol. 6437 of Lecture Notes in Computer Science, pp. 24–31. Springer Berlin / Heidelberg, Berlin, Heidelberg [Online]. DOI: 10.1007/978-3-642-16761-4_3
- Seo, J., Croft, B. W. (2008) ‘Local Text Reuse Detection’. In: (Proceedings) 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’08, pp. 571–578, New York, NY, USA. ACM.
- Smith, D. A. et al. (2011) ‘Mining relational structure from millions of books: position paper’. In: (Proceedings) 4th ACM workshop on Online books, complementary social media and crowdsourcing, BooksOnline ’11, pp. 49–54, New York, USA. ACM.
- Smith, D. A. et al. (2013) ‘Infectious texts: Modeling text reuse in nineteenth-century newspapers’. In: (Proceedings) 2013 IEEE International Conference on Big Data, pp. 86–94. IEEE [Online]. DOI: 10.1109/BigData.2013.6691675
- Smith, D. A. et al. (2014) ‘Detecting and modeling local text reuse’. In: (Proceedings) 2014 IEEE/ACM Joint Conference on Digital Libraries (JCDL), pp. 183–192. IEEE.
- Viral Texts: Mapping Networks of Reprinting in 19th-Century Newspapers and Magazines.