 In April 2016 eTRAP was awarded a 20,000€ grant from the University of Göttingen for a six-month pilot project as part of the Campuslabor Digitisation initiative.
In April 2016 eTRAP was awarded a 20,000€ grant from the University of Göttingen for a six-month pilot project as part of the Campuslabor Digitisation initiative.
Premise
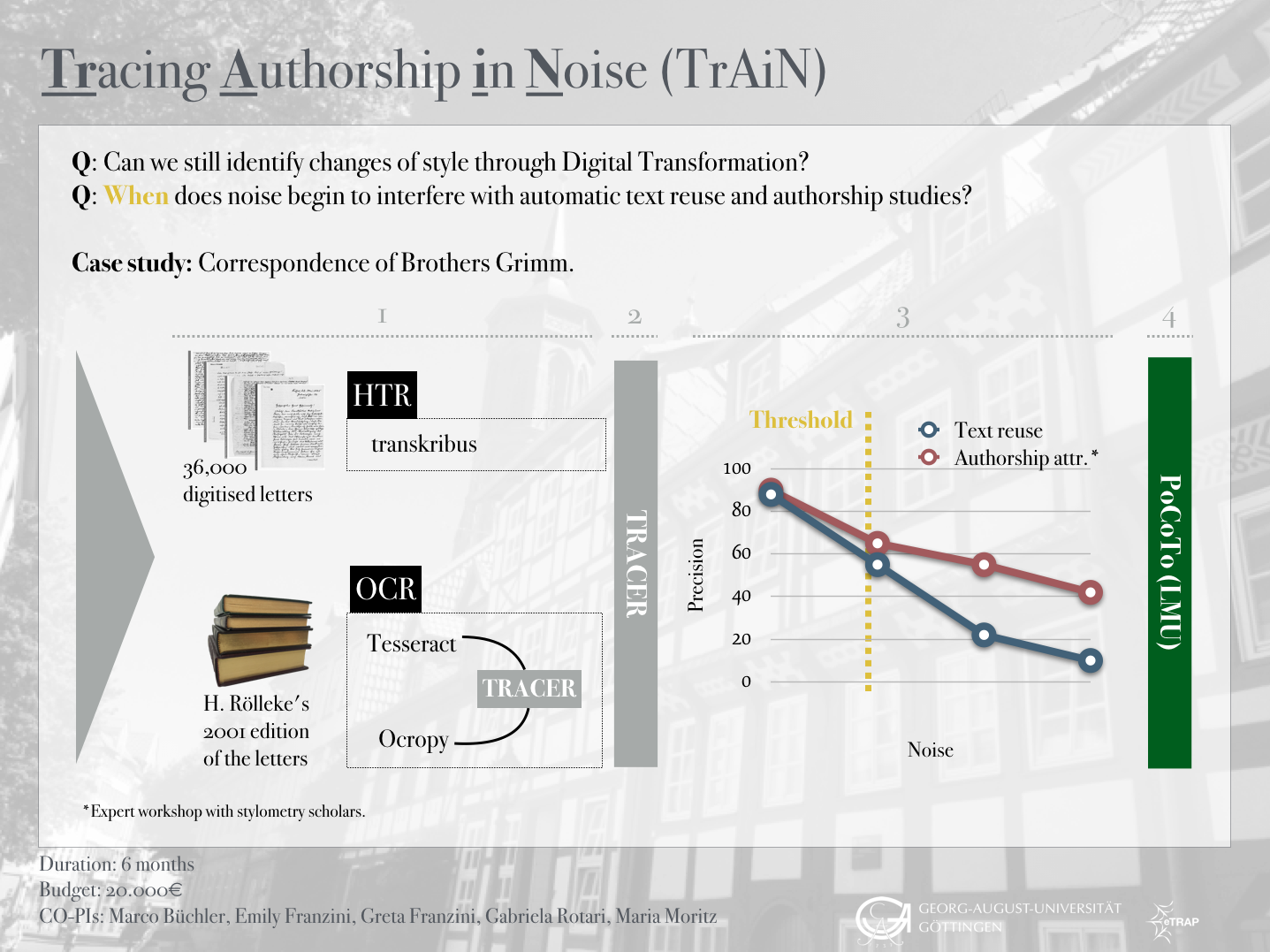
This project responded to the “Interessenbekundung zur Themenbesetzung im Campuslabor Digitalisierung” call and aimed to conduct research pertaining to two essential Digital Transformation processes, namely Optical Character Recognition (OCR) and Handwritten Text Recognition (HTR), applied to historical data. Both processes are used to produce massive –albeit noisy– digitised data to support research in textual scholarship. But in order to perform these analytical studies and automatically produce informative results, digitised text must fulfil a certain level of accuracy. In fact, too much noise or uncorrected OCR’d input can hinder retrieval tasks and affect their output. Moreover, as data pre-processing –including OCR post-correction– typically consumes up to 80% of the overall time spent on data analysis research (Wickham, 2015), scholars are often reluctant to work on noisy OCR’d texts.
Goal
TrAIN (the acronym refers to the algorithm training required for this research) sought to investigate the complex relation between digitised noisy data and automatic text analyses by way of a local case study: the vast letter collection of the Grimm Brothers, available as both digital images of the original manuscripts and as a printed edition (see below). In particular, we compared the outputs produced by the HTR of the original letters and by the OCR of the printed edition, and investigated two common scholarly tasks: text reuse detection and authorship attribution. Specifically, we used text reuse algorithms to align the OCR output with the HTR output, and author attribution techniques to identify the stylistic markers of the Grimm Brothers. While the former task focusses on content words, which are less frequent and part of the 90% of words that occur ten or fewer times, the latter primarily concentrates on frequent words, such as function words (e.g. ‘of’ or ‘the’). We used these two methods because they address two different ‘frequency domains’. Authorship attribution is much more robust on errors in the long tail of rare words, whereas text reuse detection is more dependent on cleaned data since it primarily operates on low frequency words.
Research Questions
On the one hand, we investigated and defined the maximum noise threshold that would allow us to adequately conduct authorship analyses on the texts – at which point does noise interfere with the automatic identification of stable linguistic and stylistic markers? What is the minimum amount of noise we need to correct? On the other, we ran a combination of authorship analysis techniques in order to understand whether it is possible to build a digital authorship fingerprint for both Jacob and Wilhelm Grimm regardless of handwriting and stylistic changes over time.
Case Study & Methodology
In October 2015, eTRAP acquired a copy of the digitised corpus of letters belonging to the Grimm family.1 Among these, we find many letters, which Jacob and Wilhelm Grimm –authors of the famous Kinder und Haumärchen– wrote to each other and to their acquaintances from an early age up until their death.2 These letters touch upon personal and professional matters, bearing witness to the Brothers’ life and stylistic evolution from their childhood to their role as professors and authors. We manually produced transcriptions of a selection of these letters and selected the tool Transkribus, the current state-of-the-art tool for the recognition and transcription of handwritten text, for this purpose.3 The transcriptions produced constituted the training data that enabled the automatic generation of new transcriptions. Transkribus, in fact, works in such a way that the more text it “sees” by a specific author, the more it learns to “read” new unseen text by that author. This function allows researchers to considerably speed up the time consuming transcription and preparation work necessary for research analyses. This process of transcription was complemented by an OCR process aimed at digitising the Grimm Briefwechsel, an existing critical edition of Grimm’s letter corpus.4 The benefit of having a printed collection of the letters is that it made it possible to compare the output of the automatically generated transcriptions against the manually curated finished work.
For OCR, eTRAP setup a pipeline incorporating the open source engines tesseract5 and Ocropy6. Tesseract‘s simpler models lend themselves well to large scale recognition. Ocropy, with its neural network recognisers, is often used to digitise and read difficult texts, such as those written in Fraktur. Each of these approaches has its strengths and weaknesses, calling for output aggregation in order to optimise results. With this joint setup, an accuracy of 90% or more can be achieved. For text reuse detection, we deployed our own TRACER, a text reuse framework incorporating a suite of state-of-the-art algorithms. Using text mining approaches, it automatically detects text reuse and allows the user to manually define textual relations. For the purpose of authorship attribution tasks, we used the freely available stylo8, an authorship attribution package commonly used in the Digital Humanities.
Results
The results of this research will be drafted and published between 2017 and 2018.
Project information
Project Co-PIs: Marco Büchler, Greta Franzini, Emily Franzini, Gabriela Rotari, Maria Moritz.
Project transcribers: Linda Brandt, Melina Jander, Svenja Walkenhorst.
Project duration: 1 July 2016 – 31 December 2016.
Notes
- A total of 36,000 TIFF files purchased, together with publishing rights, from the Hessen State Archives in Marburg. Available at: http://www.unimarburg.de/uniarchiv/grimm (Accessed: 16 November 2015).
- Jacob (1785-1863) and Wilhelm Grimm (1786-1859) were German researchers, academics and authors who collected and published folklore tales during the 19th century.
- Transkribus is a Transcription and Recognition Platform (TRP) whose main objective is to support users engaging in the transcription of printed and handwritten documents. It offers tools for Handwritten Text Recognition (HTR), Layout Analysis, Document Understanding, and Writer Identification. Available at: https://transkribus.eu/Transkribus/ (Accessed: 16 November 2015).
- More information available at: http://www.grimmbriefwechsel.de/ (Accessed: 16 November 2015). A copy of the critical edition is held at the SUB Göttingen.
- Available at: https://code.google.com/p/tesseractocr/ (Accessed: 16 November 2015).
- Available at: https://pypi.python.org/pypi/ocropy (Accessed: 16 November 2015).
- Available at: http://evllabs.com/jgaap/w/index.php/Main_Page (Accessed: 16 November 2015).
- Available at: https://sites.google.com/site/computationalstylistics/ (Accessed: 17 November 2015).
Works cited
- Burrows, J. (2002) ‘‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship ’, Literary and Linguistic Computing, 17(3), pp. 267-87 [Online]. DOI: 10.1093/llc/17.3.267
- Wickham, H. (2015) Tidy Data. Available at: https://cran.rproject.org/web/packages/tidyr/vignettes/tidydata.html (Accessed: 16 November 2015).