We are very pleased to announce that eTRAP has been awarded a 20,000€ grant from the University of Göttingen for a six-month pilot project. The project, TrAiN(Tracing Authorship in Noise), seeks to investigate the complex relation between noisy OCR’d data and automatic text analyses. In particular, we will investigate and attempt to define the maximum noise threshold that will allow us to adequately conduct authorship and text reuse analyses on a number of texts selected for this study. Our research questions: at which point does OCR/HTR noise interfere with the automatic identification of stable linguistic and stylistic markers? What is the minimum amount of noise we need to correct?
The project includes a joint research workshop with stylometry experts to optimise existing algorithms, and to exchange ideas and knowledge.
Congratulations, team!
Project Co-PIs: Marco Büchler, Greta Franzini, Emily Franzini, Gabriela Rotari, Maria Moritz.
As announced in late summer 2015, eTRAP ran a text reuse workshop in Tartu, Estonia, to teach participants how to run TRACER, a text reuse tool developed by Marco aimed at automatically identifying similarities between texts. Some of our participants tested TRACER on sample data we provided (English translations of the Bible); others, like Jan Rybicki, Assistant Professor at the Institute of English Studies at the Jagiellonian University of Kraków and co-organiser of Digital Humanities 2016, brought their own datasets to directly experiment with ongoing research.
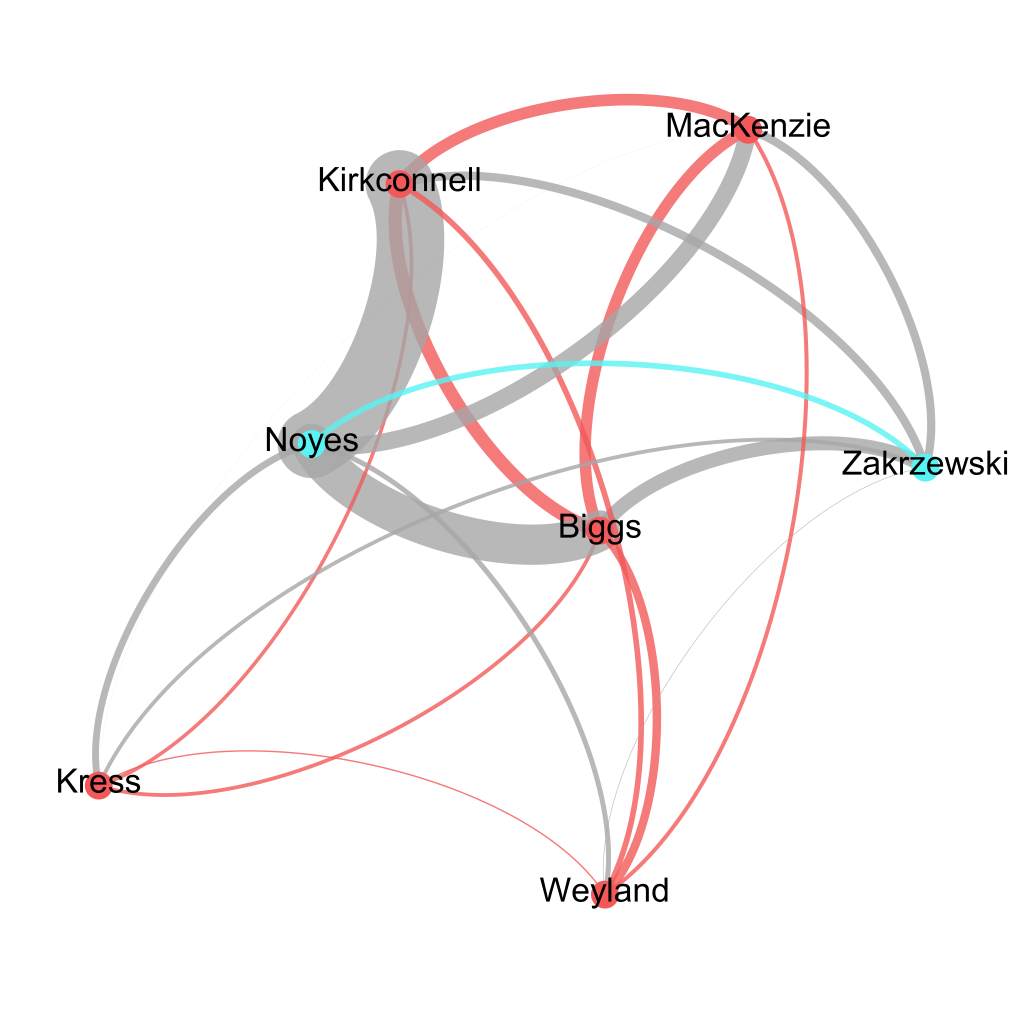
Jan has been working with seven English translations of Poland’s most significant Romantic epic poem, Pan Tadeusz by Adam Mickiewicz (1834). As an expert literary translator himself, Jan was interested in comparing these translations and to see whether TRACER could reveal any particular relationships between their authors. The translations he analysed are:
Maude Ashurst Biggs, Master Thaddeus or the Last Foray in Lithuania, London 1885 (in Miltonian blank verse)
George Rapall Noyes, Pan Tadeusz, or the Last Foray in Lithuania. A Story of Life among Polish Gentlefolk, London & Toronto, New York 1917 (prose)
Watson Kirkconnell, Sir Thaddeus or Last Foray in Lithuania: a History of the Nobility in the Years 1811 and 1812 in Twelve Books of Verse, 1962 (verse, based on Noyes)
Kenneth R. Mackenzie, Pan Tadeusz or the Last Foray in Lithuania, a Tale of the Gentry in Years 1811 and 1812, London 1964 (iambic pentameter)
Marcel Weyland, Pan Tadeusz or the Last Foray in Lithuania, a Tale of the Gentry During 1811 – 1812, Blackheath, NSW 2004 (verse)
Leonard Kress, Pan Tadeusz or the Last Foray in Lithuania: a History of the Nobility in the Years 1811 and 1812 in Twelve Books of Verse, Philadelphia 2006 (10 syllables with 5 stresses, with alternating rhymes)
Christopher Adam Zakrzewski, Pan Tadeusz or the Last Foray in Lithuania: A Tale of the Minor Nobility in the Years 1811–1812, New York 2010 (prose)
After an automatic lemmatisation all of the above texts, TRACER confirmed existing knowledge surrounding these texts but also provided a detailed overview of the degree of similarity between each pair of translations using its integrated TRAViz tool. Among other things, the fact that Kirkconnell based his verse translation on Noyes’ prose is very visible! Distant reading by TRACER also confirms that Kress’ translation differs from the others.
Jan also produced a more general view of the degrees of similarity between text pairs derived from TRACER with a Gephi network analysis (below).
Gephi network of Pan Tadeusz TRACER scores (by Jan Rybicki).
Jan’s experiments with English translations of Polish literature demonstrate the potential of TRACER for translation studies. We’re delighted to see this application of TRACER and look forward to hearing more about Jan’s research!
If you’d also like to run TRACER on your data, please contact Marco Büchler. We’d love to learn more about your research and to briefly describe your experience in a blogpost.
The Göttingen Dialog in Digital Humanities has established a forum for the discussion of digital methods applied to all areas of the Humanities and Social Sciences, including Classics, Philosophy, History, Literature, Law, Languages, Archaeology and more. The initiative is organized by the Göttingen Centre for Digital Humanities (GCDH) with the involvement of DARIAH.EU.
The dialogs will take place every Monday from April 11th until early July 2016 in the form of 90-minute seminars. Presentations will be 45 minutes long and delivered in English, followed by 45 minutes of discussion and student participation. Seminar content should be of interest to humanists, digital humanists, librarians and computer scientists. Furthermore, we proudly announce that Prof. Dr. Stefan Gradmann (KU Leuven) will be giving the opening keynote on April 11th.
We invite submissions of abstracts describing research which employs digital methods, resources or technologies in an innovative way in order to enable a better or new understanding of the humanities, both in the past and present. We also encourage contributions describing ‘work-in-progress’. Themes may include – but are not limited to – text mining, machine learning, network analysis, time series, sentiment analysis, agent-based modelling, lexical and conceptual resources for DH, or efficient visualization of big and humanities-relevant data.
On Thursday 12th November Marco will be giving a talk at the Göttingen Computer Science Cookie Seminar series entitled “Digital Humanities for Computer Scientists … or: How I became infected with the Indiana Jones virus”. Here the abstract of his talk:
Many definitions have been formulated to describe the Digital Humanities, driven either by political interests or born out of one’s own approach to it. This cookie talk describes my understanding of the Digital Humanities as an IT person and aims to show what computer scientists can contribute to our cultural heritage. The talk summarises several applications and developments that have been designed by my teams and me since 2008.
Coordinates:
Location: Institute for Computer Science, Goldschmidtstraße 7, 37077 Göttingen, seminar room 0.101
Time: November 12th, 2015, 8 PM
Link: Cookie seminar
Indiana Jones on Atari 520ST. Source: Flickr. (CC BY 2.0, no changes made).
This article describes the development and application of an innovative tool, Text Re-use Alignment Visualization (TRAViz), whose aim is to visualize variation between editions of both historical and modern texts. Reading different editions of a text empowers research in literary studies and linguistics, where one can study a text’s reception or follow the development of its language over time. One of the purposes of a text edition is to trace or reconstruct a possible archetype or something that might be considered to be an original version of the text in order to better understand its evolution over time. To do so, the textual scholar examines and records the similarities and the differences between a number of exemplars in what is known as a ‘critical apparatus’. The result of this variant analysis can be visually represented as a ‘Variant Graph’, where the relationships between these exemplars can be more easily studied. Variant Graphs can be, in turn, visualized in order to facilitate reading and interaction with the source data. Borrowing from existing digital tools, TRAViz assists the scholar in the collation process by specifically focusing on design and user engagement, concurrently seeking to simplify interaction as a means of encouraging humanists to adopt the tool. The article will describe the needs and rationale behind the creation of TRAViz by exploring existing research, describing its functionality through examples, and by finally discussing how its application can influence future development of this tool in particular and of the field in general.
JDMDH Call for Contribution: Special Issue on Computer-Aided Processing of Intertextuality in Ancient Languages
“Europe’s future is digital”. This was the headline of a speech given at the Hannover exhibition in April 2015 by Günther Oettinger, EU-Commissioner for Digital Economy and Society. While businesses and industries have already made major advances in digital ecosystems, the digital transformation of texts stretching over a period of more than two millennia is far from complete. On the one hand, mass digitisation leads to an „information overload“ of digitally available data; on the other, the “information poverty” embodied by the loss of books and the fragmentary state of ancient texts form an incomplete and biased view of our past. In a digital ecosystem, this coexistence of data overload and poverty adds considerable complexity to scholarly research.
Find the full announcement below:
—————————————————————————————————————————————-
eTRAP (Electronic Text Reuse Acquisition Project) is an Early Career Research Group funded by the German Federal Ministry of Education and Research (BMBF) and based at the Göttingen Centre for Digital Humanities at the University of Göttingen. The research group, which started on 1st March 2015, was awarded €1.6 million and runs for four years. As the name suggests, this interdisciplinary team studies the linguistic and literary phenomenon that is text reuse with a particular focus on historical languages. More specifically, we look at how ancient authors copied, alluded to, paraphrased and translated each other as they spread their knowledge in writing. This early career research group seeks to provide a basic understanding of the (historical) text reuse methodology (it being distinct from plagiarism), and so to study what defines text reuse, why some people reuse information, how text is reused and how this practice has changed over history.
The Hackathon week is over and looking back on it the eTRAP team agrees…it was a hit!
23 participants from 15 different institutions and 8 countries hacking away at research questions on their laptops to achieve the same goal, albeit with different datasets. And the goal was achieved. Our hackers were humanists with a desire to find textual reuses across different works of the same author or across several authors from different times and locations. They brought data in English, German, Latin, Sanskrit, Hebrew and even Arabic and Estonian, spanning across many genres – from folkloristic poetry, to narratives and letters, from lists of citations to biblical texts. From day one they were led by computer scientist and leader of eTRAP, Marco Büchler, through each of the six steps required by the TRACER tool (1) to perform scans of the texts in search of reuse. By using the command line like pros, hackers preprocessed their data and set the parameters they needed to guarantee the most informative outcome. The week culminated with a tutorial on TRAViz (2), an open source variant graph visualisation tool created and presented by Stefan Jänicke (3), which allows users to create a swish visualisation with the results yielded by the TRACER tool.
We present an overview of the last ten years of research on visualizations that support close and distant reading of textual data in the digital humanities. We look at various works published within both the visualization and digital humanities communities. We provide a taxonomy of applied methods for close and distant reading, and illustrate approaches that combine both reading techniques to provide a multifaceted view of the data. Furthermore, we list toolkits and potentially beneficial visualization approaches for research in the digital humanities. Finally, we summarize collaboration experiences when developing visualizations for close and distant reading, and give an outlook on future challenges in that research area.
As the first series of the Göttingen Dialog in Digital Humanities (GDDH) has just come to a close (sob!), it’s time for us to take a few minutes to reflect on its outcome and on the things we’d like to bring to the next series.
GDDH turned out to be a great success! We did not only accept 14 full papers from 11 institutions in 5 countries, but have secured a deal with Digital Humanities Quarterly to publish each contribution in a special issue. The series touched upon numerous different fields, joint by the thread that is Digital Humanities: Digital Classics, Topic Modelling, Text Visualisation, Digital Editions, 3D Motion Capture, Social Networks, Television Media, Web History, Digital Collections, Geographic Information Systems and Text Mining… (*catches breath*) WOW! We’re also currently busy evaluating the best paper and presentation – the winner, who will receive a 500€ cash prize, will be announced very soon.
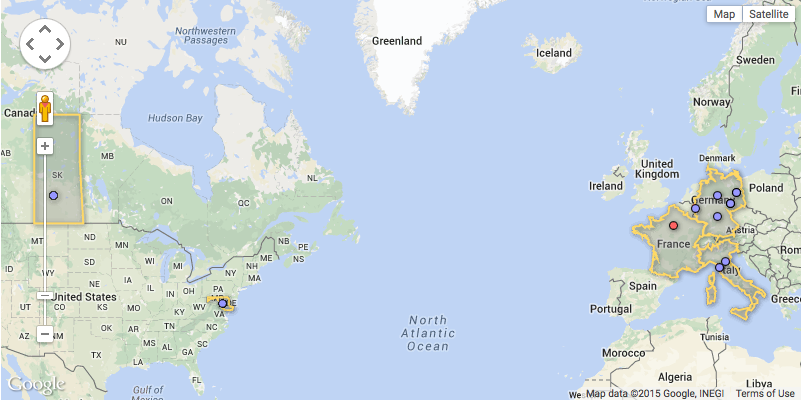
GDDH 2015 speakers: dots correspond to affiliations of speakers; dot colour represents gender. [Click the image to view the interactive version, where you can find more detailed information].