Melina Jander, an eTRAP Research Assistant, has written a short user report on our experience with the Handwritten Text Recognition (HTR) tool Transkribus. We’re currently using Transkribus as part of our pilot project TrAIN (Tracing Authorship In Noise), which aims at defining the noise-threshold that affects computational analyses on HTR’d and OCR’d texts . How much noise do we have to correct? How much can we leave in?
The report describes progress made thus far. A second report will be published in 2017 to report on Transkribus‘ automation process on our data.
The latest Digital Humanities monograph published by Open Book Publishers, Digital Scholarly Editing: Theories and Practices, includes a chapter written by Greta together with Melissa Terras and Simon Mahony from the UCL Centre for Digital Humanities. The chapter is entitled A Catalogue of Digital Editions and reports on an homonymous ongoing project that collects and analyses digital editions in an attempt to identify best practice in digital scholarly editing.
Greta will be presenting the Catalogue of Digital Editions project in the form of a poster at the upcoming Text Encoding Initiative conference in Vienna.
Greta’s latest article “Visual Text Analysis in Digital Humanities“, co-authored with Stefan Jänicke, Muhammad Faisal Cheema and Gerik Scheuermann, has just been published by the Computer Graphics Forum! Here is the abstract:
In 2005, Franco Moretti introduced Distant Reading to analyze entire literary text collections. This was a rather revolutionary idea compared to the traditional Close Reading, which focuses on the thorough interpretation of an individual work. Both reading techniques are the prior means of Visual Text Analysis. We present an overview of the research conducted since 2005 on supporting text analysis tasks with close and distant reading visualizations in the digital humanities. Therefore, we classify the observed papers according to a taxonomy of text analysis tasks, categorize applied close and distant reading techniques to support the investigation of these tasks and illustrate approaches that combine both reading techniques in order to provide a multi-faceted view of the textual data. In addition, we take a look at the used text sources and at the typical data transformation steps required for the proposed visualizations. Finally, we summarize collaboration experiences when developing visualizations for close and distant reading, and we give an outlook on future challenges in that research area.
A full-day text reuse tutorial aimed at teaching participants how to run our TRACER tool (11th July).
We’re very happy that all three proposals were accepted at the conference as each approaches our research from a different angle: during the panel, we will discuss our work in relation to other initiatives in digital folkloristics; the poster will provide a snapshot of the project as a whole; and the tutorial will give an insight into part of our research methodology, which employs a powerful text reuse engine called TRACER.
We look forward to sharing our progress in Kraków and to seeing you, hopefully!
We are very pleased to announce that eTRAP has been awarded a 20,000€ grant from the University of Göttingen for a six-month pilot project. The project, TrAiN(Tracing Authorship in Noise), seeks to investigate the complex relation between noisy OCR’d data and automatic text analyses. In particular, we will investigate and attempt to define the maximum noise threshold that will allow us to adequately conduct authorship and text reuse analyses on a number of texts selected for this study. Our research questions: at which point does OCR/HTR noise interfere with the automatic identification of stable linguistic and stylistic markers? What is the minimum amount of noise we need to correct?
The project includes a joint research workshop with stylometry experts to optimise existing algorithms, and to exchange ideas and knowledge.
Congratulations, team!
Project Co-PIs: Marco Büchler, Greta Franzini, Emily Franzini, Gabriela Rotari, Maria Moritz.
As announced in late summer 2015, eTRAP ran a text reuse workshop in Tartu, Estonia, to teach participants how to run TRACER, a text reuse tool developed by Marco aimed at automatically identifying similarities between texts. Some of our participants tested TRACER on sample data we provided (English translations of the Bible); others, like Jan Rybicki, Assistant Professor at the Institute of English Studies at the Jagiellonian University of Kraków and co-organiser of Digital Humanities 2016, brought their own datasets to directly experiment with ongoing research.
Jan has been working with seven English translations of Poland’s most significant Romantic epic poem, Pan Tadeusz by Adam Mickiewicz (1834). As an expert literary translator himself, Jan was interested in comparing these translations and to see whether TRACER could reveal any particular relationships between their authors. The translations he analysed are:
Maude Ashurst Biggs, Master Thaddeus or the Last Foray in Lithuania, London 1885 (in Miltonian blank verse)
George Rapall Noyes, Pan Tadeusz, or the Last Foray in Lithuania. A Story of Life among Polish Gentlefolk, London & Toronto, New York 1917 (prose)
Watson Kirkconnell, Sir Thaddeus or Last Foray in Lithuania: a History of the Nobility in the Years 1811 and 1812 in Twelve Books of Verse, 1962 (verse, based on Noyes)
Kenneth R. Mackenzie, Pan Tadeusz or the Last Foray in Lithuania, a Tale of the Gentry in Years 1811 and 1812, London 1964 (iambic pentameter)
Marcel Weyland, Pan Tadeusz or the Last Foray in Lithuania, a Tale of the Gentry During 1811 – 1812, Blackheath, NSW 2004 (verse)
Leonard Kress, Pan Tadeusz or the Last Foray in Lithuania: a History of the Nobility in the Years 1811 and 1812 in Twelve Books of Verse, Philadelphia 2006 (10 syllables with 5 stresses, with alternating rhymes)
Christopher Adam Zakrzewski, Pan Tadeusz or the Last Foray in Lithuania: A Tale of the Minor Nobility in the Years 1811–1812, New York 2010 (prose)
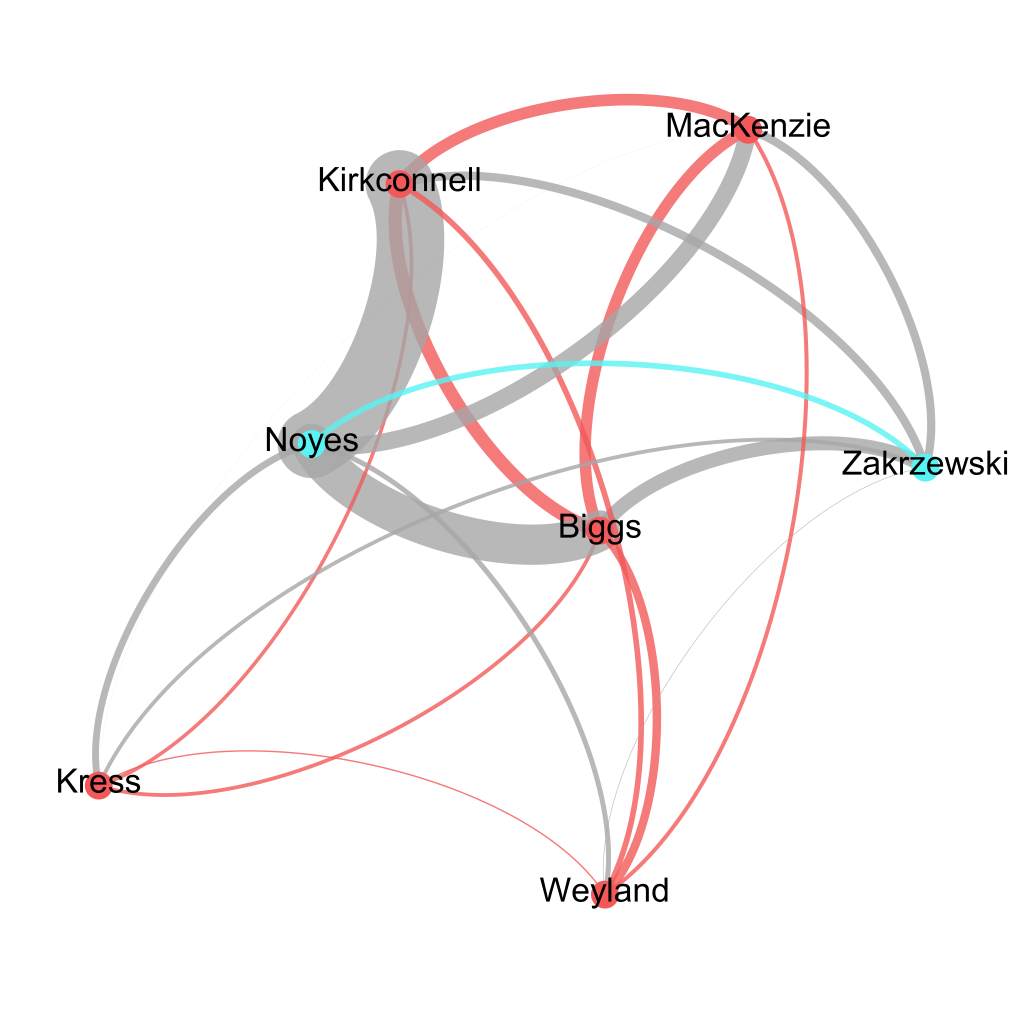
After an automatic lemmatisation all of the above texts, TRACER confirmed existing knowledge surrounding these texts but also provided a detailed overview of the degree of similarity between each pair of translations using its integrated TRAViz tool. Among other things, the fact that Kirkconnell based his verse translation on Noyes’ prose is very visible! Distant reading by TRACER also confirms that Kress’ translation differs from the others.
Jan also produced a more general view of the degrees of similarity between text pairs derived from TRACER with a Gephi network analysis (below).
Gephi network of Pan Tadeusz TRACER scores (by Jan Rybicki).
Jan’s experiments with English translations of Polish literature demonstrate the potential of TRACER for translation studies. We’re delighted to see this application of TRACER and look forward to hearing more about Jan’s research!
If you’d also like to run TRACER on your data, please contact Marco Büchler. We’d love to learn more about your research and to briefly describe your experience in a blogpost.
JDMDH Call for Contribution: Special Issue on Computer-Aided Processing of Intertextuality in Ancient Languages
“Europe’s future is digital”. This was the headline of a speech given at the Hannover exhibition in April 2015 by Günther Oettinger, EU-Commissioner for Digital Economy and Society. While businesses and industries have already made major advances in digital ecosystems, the digital transformation of texts stretching over a period of more than two millennia is far from complete. On the one hand, mass digitisation leads to an „information overload“ of digitally available data; on the other, the “information poverty” embodied by the loss of books and the fragmentary state of ancient texts form an incomplete and biased view of our past. In a digital ecosystem, this coexistence of data overload and poverty adds considerable complexity to scholarly research.
Find the full announcement below:
—————————————————————————————————————————————-
eTRAP (Electronic Text Reuse Acquisition Project) is an Early Career Research Group funded by the German Federal Ministry of Education and Research (BMBF) and based at the Göttingen Centre for Digital Humanities at the University of Göttingen. The research group, which started on 1st March 2015, was awarded €1.6 million and runs for four years. As the name suggests, this interdisciplinary team studies the linguistic and literary phenomenon that is text reuse with a particular focus on historical languages. More specifically, we look at how ancient authors copied, alluded to, paraphrased and translated each other as they spread their knowledge in writing. This early career research group seeks to provide a basic understanding of the (historical) text reuse methodology (it being distinct from plagiarism), and so to study what defines text reuse, why some people reuse information, how text is reused and how this practice has changed over history.

 eTRAP will be attending the annual
eTRAP will be attending the annual