Greta’s latest article “Visual Text Analysis in Digital Humanities“, co-authored with Stefan Jänicke, Muhammad Faisal Cheema and Gerik Scheuermann, has just been published by the Computer Graphics Forum! Here is the abstract:
In 2005, Franco Moretti introduced Distant Reading to analyze entire literary text collections. This was a rather revolutionary idea compared to the traditional Close Reading, which focuses on the thorough interpretation of an individual work. Both reading techniques are the prior means of Visual Text Analysis. We present an overview of the research conducted since 2005 on supporting text analysis tasks with close and distant reading visualizations in the digital humanities. Therefore, we classify the observed papers according to a taxonomy of text analysis tasks, categorize applied close and distant reading techniques to support the investigation of these tasks and illustrate approaches that combine both reading techniques in order to provide a multi-faceted view of the textual data. In addition, we take a look at the used text sources and at the typical data transformation steps required for the proposed visualizations. Finally, we summarize collaboration experiences when developing visualizations for close and distant reading, and we give an outlook on future challenges in that research area.
(Targeted at students of German Literature or other Humanities subjects)
The early career research group eTRAP is looking for Student Assistants. The research group is associated with the Institute of Computer Science and operates from the Göttingen Centre for Digital Humanities (GCDH). Further information about the research group and its work can be found at https://www.etrap.eu.
Job description
We are looking for applicants interested in joining the research group on TrAIN, a new project which was recently awarded the sum of €20,000 by the University of Göttingen. TrAIN, which stands for Tracing Authorship in Noise, will run for the duration of six months from 1st June 2016. The aim of the project is to obtain digital and searchable copies of the original correspondence of the Grimm brothers – the famous authors of the Kinder- und Hausmärchen. The digital copies will be obtained in two different ways, namely by the use of an HTR (Handwritten Text Recognition) tool and multiple OCR (Optical Character Recognition) tools. The output of such work will then be used to further research in the fields of stylometry and authorship attribution.
We are hiring 2 students for the duration of 3 months (extendable contract) who will act as the transcribers of the team. They will work with Transkribus, an HTR tool used to transcribe handwritten texts.
A full-day text reuse tutorial aimed at teaching participants how to run our TRACER tool (11th July).
We’re very happy that all three proposals were accepted at the conference as each approaches our research from a different angle: during the panel, we will discuss our work in relation to other initiatives in digital folkloristics; the poster will provide a snapshot of the project as a whole; and the tutorial will give an insight into part of our research methodology, which employs a powerful text reuse engine called TRACER.
We look forward to sharing our progress in Kraków and to seeing you, hopefully!
We are very pleased to announce that eTRAP has been awarded a 20,000€ grant from the University of Göttingen for a six-month pilot project. The project, TrAiN(Tracing Authorship in Noise), seeks to investigate the complex relation between noisy OCR’d data and automatic text analyses. In particular, we will investigate and attempt to define the maximum noise threshold that will allow us to adequately conduct authorship and text reuse analyses on a number of texts selected for this study. Our research questions: at which point does OCR/HTR noise interfere with the automatic identification of stable linguistic and stylistic markers? What is the minimum amount of noise we need to correct?
The project includes a joint research workshop with stylometry experts to optimise existing algorithms, and to exchange ideas and knowledge.
Congratulations, team!
Project Co-PIs: Marco Büchler, Greta Franzini, Emily Franzini, Gabriela Rotari, Maria Moritz.
eTRAP’s article “Sentence Shortening via Morpho-Syntactic Annotated Data in Historical Language Learning” authored by Maria Moritz, Barbara Pavlek, Greta Franzini and Gregory Crane, is now published in the current issue of the ACM Journal on Computing and Cultural Heritage (JOCCH). The work was supported by the Federal Ministry of Education (BMBF) and the European Social Fund (ESF). Here is the abstract:
We present an approach to shorten Ancient Greek sentences by using morpho-syntactic information attached to each word in a sentence. This work underpins the content of our eLearning application, AncientGeek, whose unique teaching technique draws from primary Greek sources. By applying a technique that skips the clausal dependents of a main verb, we reached a well-formed rate of 89% of the sentences.
As announced in late summer 2015, eTRAP ran a text reuse workshop in Tartu, Estonia, to teach participants how to run TRACER, a text reuse tool developed by Marco aimed at automatically identifying similarities between texts. Some of our participants tested TRACER on sample data we provided (English translations of the Bible); others, like Jan Rybicki, Assistant Professor at the Institute of English Studies at the Jagiellonian University of Kraków and co-organiser of Digital Humanities 2016, brought their own datasets to directly experiment with ongoing research.
Jan has been working with seven English translations of Poland’s most significant Romantic epic poem, Pan Tadeusz by Adam Mickiewicz (1834). As an expert literary translator himself, Jan was interested in comparing these translations and to see whether TRACER could reveal any particular relationships between their authors. The translations he analysed are:
Maude Ashurst Biggs, Master Thaddeus or the Last Foray in Lithuania, London 1885 (in Miltonian blank verse)
George Rapall Noyes, Pan Tadeusz, or the Last Foray in Lithuania. A Story of Life among Polish Gentlefolk, London & Toronto, New York 1917 (prose)
Watson Kirkconnell, Sir Thaddeus or Last Foray in Lithuania: a History of the Nobility in the Years 1811 and 1812 in Twelve Books of Verse, 1962 (verse, based on Noyes)
Kenneth R. Mackenzie, Pan Tadeusz or the Last Foray in Lithuania, a Tale of the Gentry in Years 1811 and 1812, London 1964 (iambic pentameter)
Marcel Weyland, Pan Tadeusz or the Last Foray in Lithuania, a Tale of the Gentry During 1811 – 1812, Blackheath, NSW 2004 (verse)
Leonard Kress, Pan Tadeusz or the Last Foray in Lithuania: a History of the Nobility in the Years 1811 and 1812 in Twelve Books of Verse, Philadelphia 2006 (10 syllables with 5 stresses, with alternating rhymes)
Christopher Adam Zakrzewski, Pan Tadeusz or the Last Foray in Lithuania: A Tale of the Minor Nobility in the Years 1811–1812, New York 2010 (prose)
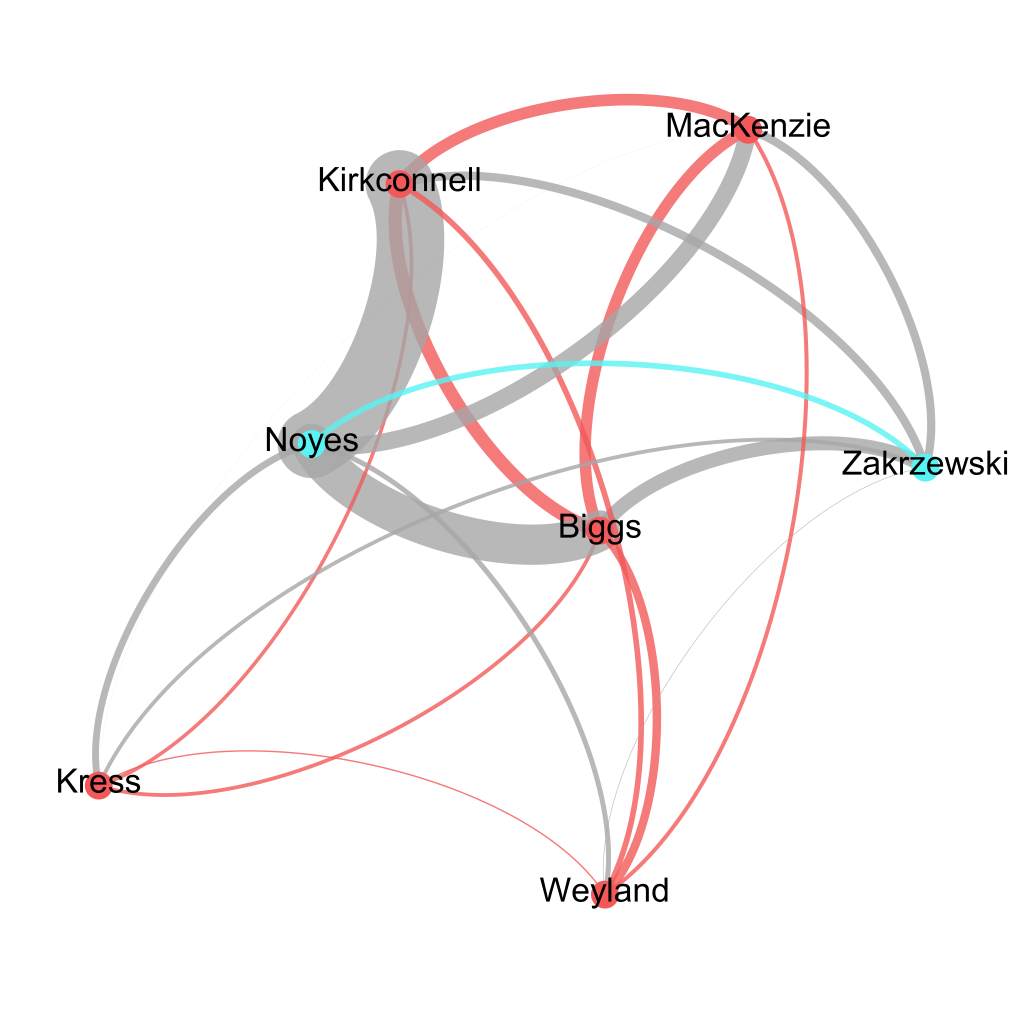
After an automatic lemmatisation all of the above texts, TRACER confirmed existing knowledge surrounding these texts but also provided a detailed overview of the degree of similarity between each pair of translations using its integrated TRAViz tool. Among other things, the fact that Kirkconnell based his verse translation on Noyes’ prose is very visible! Distant reading by TRACER also confirms that Kress’ translation differs from the others.
Jan also produced a more general view of the degrees of similarity between text pairs derived from TRACER with a Gephi network analysis (below).
Gephi network of Pan Tadeusz TRACER scores (by Jan Rybicki).
Jan’s experiments with English translations of Polish literature demonstrate the potential of TRACER for translation studies. We’re delighted to see this application of TRACER and look forward to hearing more about Jan’s research!
If you’d also like to run TRACER on your data, please contact Marco Büchler. We’d love to learn more about your research and to briefly describe your experience in a blogpost.
The Göttingen Dialog in Digital Humanities has established a forum for the discussion of digital methods applied to all areas of the Humanities and Social Sciences, including Classics, Philosophy, History, Literature, Law, Languages, Archaeology and more. The initiative is organized by the Göttingen Centre for Digital Humanities (GCDH) with the involvement of DARIAH.EU.
The dialogs will take place every Monday from April 11th until early July 2016 in the form of 90-minute seminars. Presentations will be 45 minutes long and delivered in English, followed by 45 minutes of discussion and student participation. Seminar content should be of interest to humanists, digital humanists, librarians and computer scientists. Furthermore, we proudly announce that Prof. Dr. Stefan Gradmann (KU Leuven) will be giving the opening keynote on April 11th.
We invite submissions of abstracts describing research which employs digital methods, resources or technologies in an innovative way in order to enable a better or new understanding of the humanities, both in the past and present. We also encourage contributions describing ‘work-in-progress’. Themes may include – but are not limited to – text mining, machine learning, network analysis, time series, sentiment analysis, agent-based modelling, lexical and conceptual resources for DH, or efficient visualization of big and humanities-relevant data.
On Thursday 12th November Marco will be giving a talk at the Göttingen Computer Science Cookie Seminar series entitled “Digital Humanities for Computer Scientists … or: How I became infected with the Indiana Jones virus”. Here the abstract of his talk:
Many definitions have been formulated to describe the Digital Humanities, driven either by political interests or born out of one’s own approach to it. This cookie talk describes my understanding of the Digital Humanities as an IT person and aims to show what computer scientists can contribute to our cultural heritage. The talk summarises several applications and developments that have been designed by my teams and me since 2008.
Coordinates:
Location: Institute for Computer Science, Goldschmidtstraße 7, 37077 Göttingen, seminar room 0.101
Time: November 12th, 2015, 8 PM
Link: Cookie seminar
Indiana Jones on Atari 520ST. Source: Flickr. (CC BY 2.0, no changes made).
This article describes the development and application of an innovative tool, Text Re-use Alignment Visualization (TRAViz), whose aim is to visualize variation between editions of both historical and modern texts. Reading different editions of a text empowers research in literary studies and linguistics, where one can study a text’s reception or follow the development of its language over time. One of the purposes of a text edition is to trace or reconstruct a possible archetype or something that might be considered to be an original version of the text in order to better understand its evolution over time. To do so, the textual scholar examines and records the similarities and the differences between a number of exemplars in what is known as a ‘critical apparatus’. The result of this variant analysis can be visually represented as a ‘Variant Graph’, where the relationships between these exemplars can be more easily studied. Variant Graphs can be, in turn, visualized in order to facilitate reading and interaction with the source data. Borrowing from existing digital tools, TRAViz assists the scholar in the collation process by specifically focusing on design and user engagement, concurrently seeking to simplify interaction as a means of encouraging humanists to adopt the tool. The article will describe the needs and rationale behind the creation of TRAViz by exploring existing research, describing its functionality through examples, and by finally discussing how its application can influence future development of this tool in particular and of the field in general.
The board of the Göttingen Dialog in Digital Humanities is pleased to announce the winners of this year’s dialog series award. The winner will be handed a prize of €500 and candidates in the second and third position will receive a notable mention.
The winner of the seminar series of 2015 is the paper:
Automated Pattern Analysis in Gesture Research: Similarity Measuring in 3D Motion Capture Models of Communicative Action
by
Daniel Schüller et al.
in combination with the presentation given by
Daniel Schüller, Christian Beecks & Irene Mittelberg
from RWTH Aachen University, Germany and University of Alberta, Canada
on 23rd June
The prize is awarded on the basis of an evaluation of both the paper and the quality of the presentation, for which this candidate received 85/100. “It was awesome”, “Valuable for studying the meaning of gestures”, are comments accompanying the scores, which were given for content quality, significance for theory or practice, level ofinnovation and presentation style by the reviewers of the papers, and by the audience for the presentations.
 eTRAP will be attending the annual
eTRAP will be attending the annual